
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 코드스테이츠 #알고리즘 #그리디
- React #리액트 이벤트 주기 #리액트 이벤트
- rate limit
- Next.js
- 백준 #적록색약
- html entities
- React #effect hook #useEffect
- 백준 #직각삼각형
- npm #not being able to find a file #npm install Error
- 노마드 코더 #타입스크립트 #typescript #class
- #useRef #언제 쓰는데?
- 이친수
- 얕은 복사 #깊은 복사 #shallow copy #deep copy
- 다익스트라 #파티 #백준
- useState #Hooks
- raect typescript #react #typescript #styled-component
- React-Query
- 버블링 #갭쳐링 #이벤트 #JS
- React #controlled component #비제어 컴포넌트 #제어 컴포넌트
- React #Hook rules #Hook 규칙
- JWT #토큰 #refreshToken #accessToken #Token #token #localStorage #sessionStorage
- axios
- interceptors
- RateLimit
- 빡킹독
- react fragment
- react #useCallback #react Hook
- donwstream #upstream #origin
- 플로이드 #c++
- DP #c++
- Today
- Total
꿈꾸는 개발자
React-Query (아케텍처/사용법 정리-추가 예정) 본문
react-query는 아래와 같은 기능들을 보다 간편하게 할 수 있도록 도와준다(그 외에도 다양한 기능을 제공). 해당 기능들을 통해 클라이언트 상태와 서버 상태를 명확하게 구분을 해준다.
- 서버 상태 가져오기
- 캐싱
- 동기화 및 업데이트
사용하는 이유
우아한테크세미나(보다 자세한 내용은 관련 링크를 참고하세요)
우테크 세미나 내용을 참고해보면, 직관적인 API 호출, 서버 상태관리의 용이성, client side에 정제된 상태 관리 등 다양한 이유들이 나온다.
개인적인 이유:
아직 사용해보지 않았기 때문에 관련 내용들이 얼마나 강력한 편의성을 제공할지 알지 못하지만 개인적으로 팀 프로젝트를 진행하면서 redux-toolkit을 통해 비동기 데이터를 처리 시도를 할 때 이것을 관리하는 것이 상당히 애매하다는 것을 많이 느꼈다. 단순히 직접적으로 서버와 fetch 즉 통신을 하면 되는 것을 thunk를 이용해 욱여 넣는 식으로 상태 관리를 하는 것이 맞는가?란 회의감이 들었다. thunk를 이용해서 서버의 데이터를 관리하고자 할 때 들었던 방법은 총 2가지이다
- 모든 fetch를 thunk를 통해서 관리 (GET,POST 등): 하지만 이럴 경우 바로 fetch하면 되는 것을 굳이 redux를 사용해보겠다. 억지로 사용하는 느낌이 너무 강하게 들었다. 이렇게 사용하는 게 맞나?란 생각도 많이 했던 것 같다.
- fetch는 redux로 post는 그냥 직접적으로 하는 방식을 생각했지만, 해당 방식 또한 클라이언트/서버 간의 데이터 불일치가 발생해 적절한 방법이라 생각들지 않았다.
위와 같이 수많은 고민을 안고 프로젝트를 진행했지만 결국 해결되지 못한 채 (기간이 정해진 프로젝트라....) 끝이 나버렸다. 현업 개발자와 질의응답을 나눌 기회가 생겼는데 그때 위의 고민을 나눴을 때 그 분께서는 현업에서는 관련 이슈들을 react-query로 처리한다고 관련해서 공부해보라고 조언해주셨다. 그전까지 reqact-query에 대해서 많이 들오봤지만 정확한 내용에 대해서 알지 못했다. 나중에 꼭 공부를 해봐야지 막연하게 생각하고 있었지만, 이렇게 내가 실제로 겪은 고민을 해결하기 위해선 더 이상 미루면 안 될 것이라 판단되어 관련 내용을 작성하려 한다.
react-query 아키텍처
일단새로운 스택을 도입할 때 개인적으로 가장 빠르게 배우는 방법은 아키텍처를 파악하는 것이라고 생각한다. redux의 경우도 전체적인 아키텍처가 머리에 그려졌을 때 조금 더 수월하게 배웠던 것 같다. 따라서 우선 react-query와 관련된 내용을 정리하기 전 전체적인 아키텍처에 대해서 정리하고자 한다.
The QueryClient
import { QueryClient, QueryClientProvider } from '@tanstack/react-query'
// ⬇️ this creates the client
const queryClient = new QueryClient()
function App() {
return (
// ⬇️ this distributes the client
<QueryClientProvider client={queryClient}>
<RestOfYourApp />
</QueryClientProvider>
)
}QueryClientProvider를 위와 같이 전역 적용을 하게 되면 애플리케이션 시작 시 QueryClient를 어디에서든지 접근이 가능하게 된다(React Context를 통해 이루어진다). useQueryClient를 통해 접근이 가능하다.
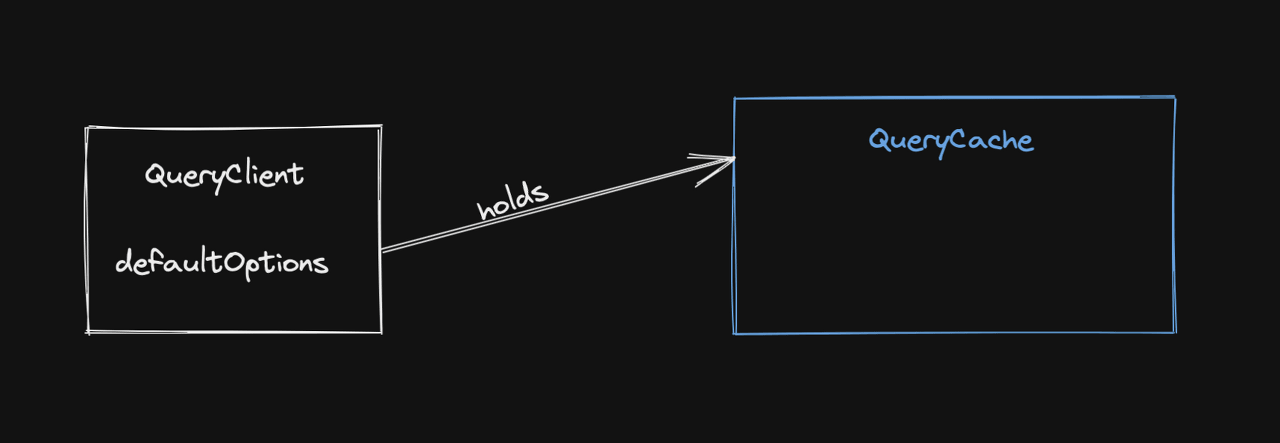
캐시를 담는 그릇
QueryClient는 QueryCache 및 MutationCache의 컨테이너 역할을 주로 담당한다. 추가로 query/mutation에 대해 설정할 할 수 있는 기본값을 보유하고 있다. 캐시 작업을 위한 편리한 방법을 제공한다. 대부분의 경우 QueryClient를 통해 Cache에 접근한다.
QueryCache
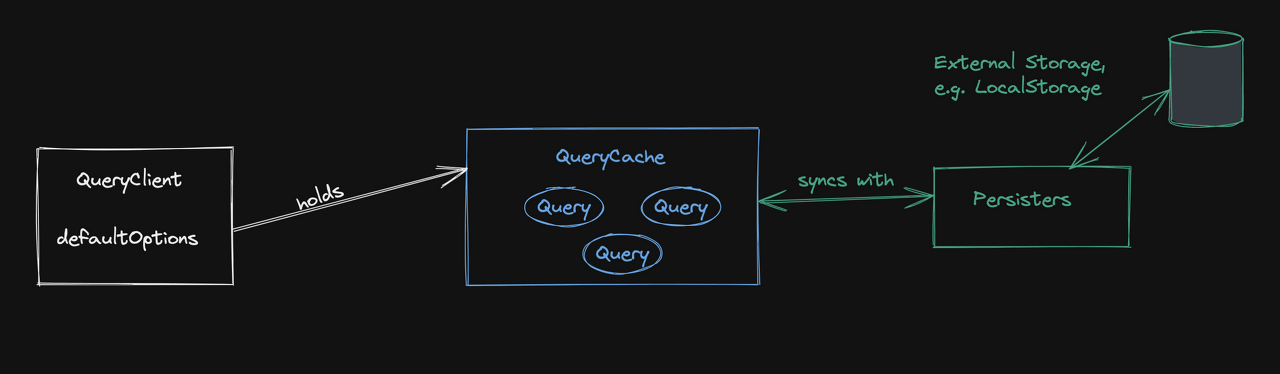
QueryCache는 메모리 내 객체이며 객체 키들은 직렬화된 queryKeys들이고, 값은 Query 클래스의 인스턴스이다. react-query의 중요한 점은 데이터를 오직 in-memory에 저장된다. 따라서 새로 고침을 하게 되면 data들은 사라지게 돼 있다. 데이터 유지를 원한다면 Persisters와 관련된 추가 내용을 검색해야 한다(locaStorage와 연관됨).
Query
Query에서 많은 로직이 발생한다. Query는 모든 정보(데이터, 상태 필드, 마지막 fetch의 발생 기록 등과 같은 메타 정보를 담고 있다) 포함함과 동시에 쿼리 함수 실행, 재시도, 취소, 중복 제거가 가능하다.
퀴리에는 우리가 우리가 impossible state에 빠지지 않도록 내부 상태 머신이 존재한다. 예를 들어서, 이미 fetching하고 있는 중에 query 함수를 실행해야 한다면 해당 fetching 작업의 중복 제거가 가능하다(원문을 통해 파악했을 때 아마 중복을 해소할 수 있다는 듯?) query가 취소되면 이전 상태로 돌아가게 된다.
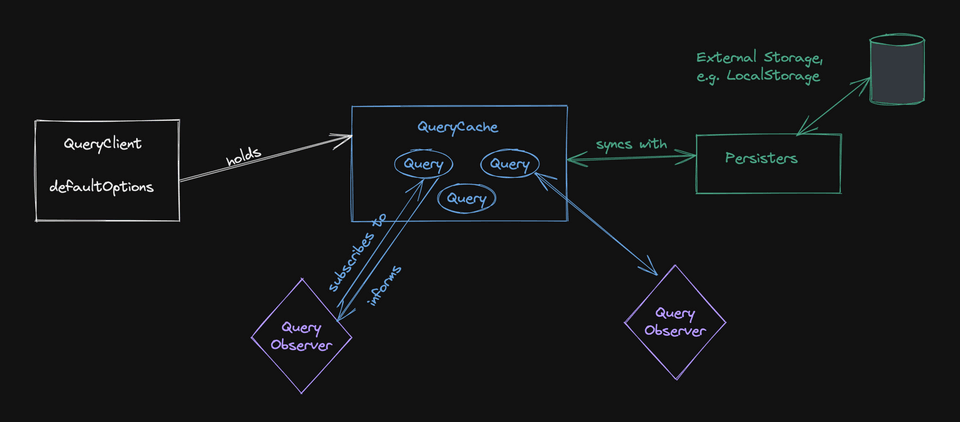
가장 중요한 것은 query는 Observers를 통해 모든 변화를 감지 할 수 있다.
QueryObserver

Observer는 Query와 해다아 Query를 사용하고자 하는 컴포넌트를 연결하는 역할을 한다. useQuery를 사용하게 되면 Observer가 생성되며 정확히 하나의 query에 바인딩 된다(queryKey를 사용하는 이유).
Observer에서 최적화가 이루어진다. Oberserver는 컴포넌트가 사용 중인 쿼리 속성을 알 수 있고 따라서, 연관되지 않은 변화를 고지할 필요가 없음. 예시로, 데이터 필드만 사용할 경우 백그라운드 refetch 때문에 re-render를 할 필요가 없어진다
select 옵션을 통해 데이터 필드의 어떤 부분에 관심을 두고 있는지 결정할 수 있다. (staleTime, interval fetching도 Observer-leve에서 발생한다)
Active and inactive Queries
Observer가 없으면 곧 비활성 쿼리. 캐시는 존재하지만 이것을 사용하는 컴포넌트가 없다는 의미이다. 비활성 쿼리는 리액트 쿼리 데브툴에서 회색으로 표시된다.

The complete picture

From a component perspective
컴포넌트 관점에서의 흐름도

- 컴포넌트 mount => Observer를 생성하는 useQuery를 호출
- Observer는 QueryCache에 있는 Queryf를 구독?바인딩?관찰한다
- 위 작업은 Query 생성(없는 경우)/벡 그라운드 fetching(오랜된 데이터일 경우)
- fetching이 진행되면 쿼리 상태가 변하기 때문에 Observer에게 관련 정보가 제공된다.
- Observer는 최적화를 진행 후 잠재적 업데이트에 대해 컴포넌트에게 알리면 새상태를 렌더링할 수 있게 된다.
- query 실행이 종료되면 Observer에게도 이 사실을 알린다.
위는 여러 흐름 중 하나를 언급한 것이다. 이상적으로는 컴포넌트가 마운트 됐을 때 데이터가 이미 캐시에 있어야 한다.
# 위 내용은 원문의 한글 버전을 요약하려고 했으나, 어색한 표현들(저도 영어를 못 해서 그냥 개인적인 생각입니다). 원문과 비교해 새롭게 요약한 글입니다...
참고한 자료
Queries | TanStack Query Docs
Query Basics A query is a declarative dependency on an asynchronous source of data that is tied to a unique key. A query can be used with any Promise based method (including GET and POST methods) to fetch data from a server. If your method modifies data on
tanstack.com
https://github.com/ssi02014/react-query-tutorial#react-query-typescript
GitHub - ssi02014/react-query-tutorial: 😃 TanStack Query(aka. react query) 에서 자주 사용되는 개념 정리
😃 TanStack Query(aka. react query) 에서 자주 사용되는 개념 정리 - GitHub - ssi02014/react-query-tutorial: 😃 TanStack Query(aka. react query) 에서 자주 사용되는 개념 정리
github.com
📲 React-query 사용하는 이유, useInfiniteQuery 로 무한 스크롤 구현하기 (+ react-infinite-scroller)
현재 동료들과 함께 진행하고 있는 사이드 프로젝트에 React-query를 도입해봤습니다. React-query를 왜 사용했는지? 에 대해서 소개하고 사용 방법과 React-query를 이용하여 무한 스크롤을 구현해본 방
velog.io
https://tkdodo.eu/blog/inside-react-query
Inside React Query
Taking a look under the hood of React Query
tkdodo.eu
https://velog.io/@hyunjine/Inside-React-Query
Inside React Query
React Query가 어떻게 동작하는지 알아봅니다.
velog.io
(위에는 한글 버전)

